Distributed Compute Aggregation
One management plane for GPU compute from every source you own or contract. Whether that is a cloud region, a co-located data center, or a compute supplier, each site runs a Standalone Control Plane Cluster. Your central Platform instance sees the full fleet.
Typical stack: Central Platform (global). Per-DC Standalone Control Plane Cluster. Private GPU nodes co-located with each Standalone instance. vMetal for owned bare metal sites.
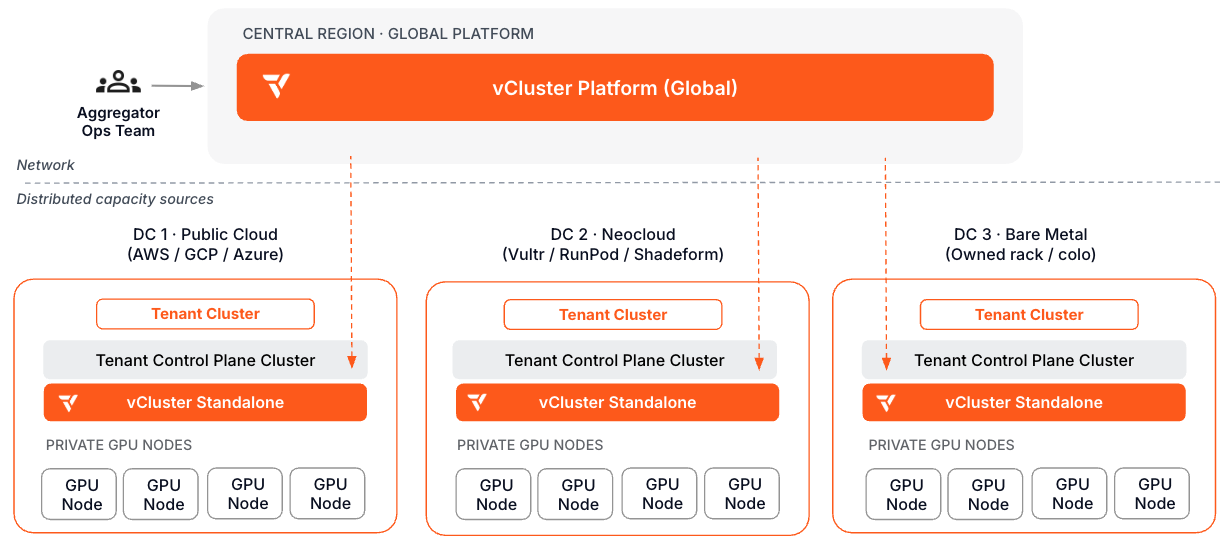
What makes this path different: Every compute source, regardless of where it lives or who operates it, follows the same onboarding playbook. One ops team, one management plane, no per-provider tooling. This architecture also maps to the cluster-level isolation criteria that AI cloud buyers evaluate in frameworks like ClusterMAX.
Day 0: Design decisions
| Decision | Read next | Outcome |
|---|---|---|
| Design the central-regional topology | Multi-region Platform, Standalone deployment | Central Platform registers each DC's Standalone instance as a connected cluster. Tenant control planes run co-located with their GPU nodes at each site. |
| Define the supplier onboarding playbook | Standalone HA, Private Nodes, Auto Nodes | Standardize the steps to register a new compute source: install Standalone, connect to central Platform, join GPU inventory, validate. |
| Plan networking between sites | VPN | Each site's tenant clusters connect to their private nodes over VPN. Define whether tenants can span sites or are bound to a single DC. |
| Define tenant isolation at each site | Private Nodes, vNode docs | Each tenant cluster at a site gets its own dedicated GPU nodes. vNode adds runtime isolation for untrusted workloads. |
Day 1: Stand up the first compute source
- Deploy vCluster Platform in the central region. Configure Platform HA and backup.
- At the first compute site, install vCluster Standalone and move to HA.
- Register the site's Standalone Control Plane Cluster with central Platform.
- Join the site's GPU inventory as private nodes. Configure Auto Nodes or vMetal for automated provisioning and reclaim.
- Configure templates and quotas in central Platform for this compute source.
- Provision a test tenant cluster at the site. Validate that it appears in central Platform and that workloads land on the correct GPU nodes.
- Document the supplier onboarding playbook. Repeat steps 2-6 for each additional compute source.
Day 2: Operate
| Operation | Read next |
|---|---|
| Monitor the distributed fleet | Fleet monitoring |
| Onboard a new compute source | Supplier onboarding playbook (internal), Standalone deployment |
| Upgrade across sites | Upgrade vCluster, upgrade Platform |
| Handle site failures | Platform HA, multi-region Platform |