Guide
AI Cloud Providers: Why the Cost of Delaying Managed Kubernetes Is Higher Than You Think
How the 12-Month Build Trap Destroys GPU ROI, and Why Partnering Gets You to Revenue in Weeks, Not Quarters
AI cloud providers can monetize bare metal, but that path limits growth and forces a low-margin, volume driven business. To capture higher value customers and expand into new use cases, providers must offer a cloud grade developer and operations experience built on managed Kubernetes. Waiting to build that platform in house creates a structural disadvantage: hardware depreciates, deals slow down, and competitors with faster time to market take the higher margin segments.
Partnering on a production ready managed Kubernetes platform converts raw capacity into a differentiated product you can price and scale. It compresses time to revenue, improves capital efficiency, and shifts scarce engineering skill away from plumbing and toward product features that actually win customers. For AI cloud providers, managed Kubernetes multiplies revenue, not just features. The decision to build or partner is first and foremost financial. Typical internal timelines push first meaningful enterprise revenue out by 8 to 12 months.
During that interval: GPU value erodes, engineering costs accumulate, enterprise opportunities go cold, and market differentiation is lost. Partnering moves production readiness from many months to a few weeks, protects asset value, lowers operational risk, and frees engineering capacity to focus on true competitive advantage.
For AI cloud providers, the question is not whether you can build a managed Kubernetes platform. Most teams can. The question is what that choice costs you in lost time, lost revenue, and lost market position, and whether you can afford to find out.
GPU infrastructure depreciates continuously. New architectures reset pricing benchmarks every 12 to 18 months. Cloud providers and hyperscalers drop prices on older SKUs aggressively. Customer demand shifts toward improved performance per dollar. This creates a simple but brutal economic truth: every month you delay monetization you are selling a less valuable asset at a lower price point.
Consider a typical scenario: a $20M GPU fleet generating a 3 percent monthly yield equals $600K in potential monthly revenue. An internal build timeline of 4 to 6 months for hiring, 6 to 8 months for architecture and build, and 2 to 4 months for production hardening pushes first meaningful revenue out 10 to 12 months. That delay represents $4.8M to $7.2M in lost revenue. That calculation understates the real cost because it assumes static pricing.
In reality, you are not just delaying revenue. You are entering the market after the highest margin opportunities have been captured, after pricing benchmarks have declined, and after competition has intensified. Early launch captures revenue near peak asset value. Late launch captures revenue after significant, irreversible value decay.
The true cost of building internally compounds across three dimensions that multiply rather than add.

The chart above illustrates a critical truth: GPU revenue potential declines continuously over time, while internal build timelines delay when revenue even begins.
Production ready infrastructure typically takes 10 to 12 months minimum. During this window, your GPUs generate no enterprise revenue while competitors onboard customers, establish pricing expectations, and build a pipeline. A realistic internal timeline:
During this period, your GPU fleet is idle or underutilized.
For example:
But the diagram highlights something even more important:
So this is not just delayed revenue, it is permanently unrecoverable revenue. You will be absorbing fixed costs against a depreciating asset with no offsetting revenue.
Unlike software, GPUs are rapidly depreciating assets tied directly to innovation cycles. Each new generation of hardware, such as next-gen NVIDIA architectures, effectively resets pricing benchmarks across the market. At the same time, cloud providers aggressively discount older SKUs, while customer demand shifts toward better performance-per-dollar options.
As a result, the theoretical value of GPUs declines steadily over time, but actual market value drops even faster due to real-world pricing pressure. This creates a compounding effect: every month of delay means you are monetizing a less valuable asset at a lower price point.
The impact is significant. Margins per GPU hour decrease, utilization drops as customers migrate to more competitive offerings, and the window for premium pricing shortens. Time-to-market is not just about speed, it is fundamentally about protecting price and preserving margin.
Compounding this further, GPU pricing itself is highly unstable. NVIDIA releases and hyperscaler pricing adjustments continuously compress margins on existing hardware. Meanwhile, AI cloud providers often offer 25 to 50 percent discounts compared to traditional cloud, placing additional downward pressure on acceptable market pricing.
By the time you reach market you are competing in a materially lower margin environment than the one you designed your business case around.
A managed Kubernetes control plane is expensive to build and does not create durable product differentiation on its own. The build typically requires a multi month recruitment cycle and a long ramp.
Recruiting friction and replacement risk matter. Typical hiring reality looks like:
If 4 to 6 senior engineers work for a year to deliver platform primitives, the fully loaded cost is roughly $1.0M to $2.1M per year. In a larger build scenario, 6 to 10 senior engineers is common, pushing annual engineering burn toward $1.5M to $2.5M or more.
Beyond the salary math, this is misallocated engineering capital. Those engineers are building lifecycle management, networking, autoscaling, observability, multi tenancy, and isolation that customers expect as table stakes.
Meanwhile they are not working on workload optimizations, pricing innovation, vertical features, or customer experience improvements that actually win deals. Hiring time and ramp time are often a critical path for the project timeline, and replacement cost amplifies schedule risk.
What the diagram ultimately shows is a triple penalty:
These effects multiply, not add.
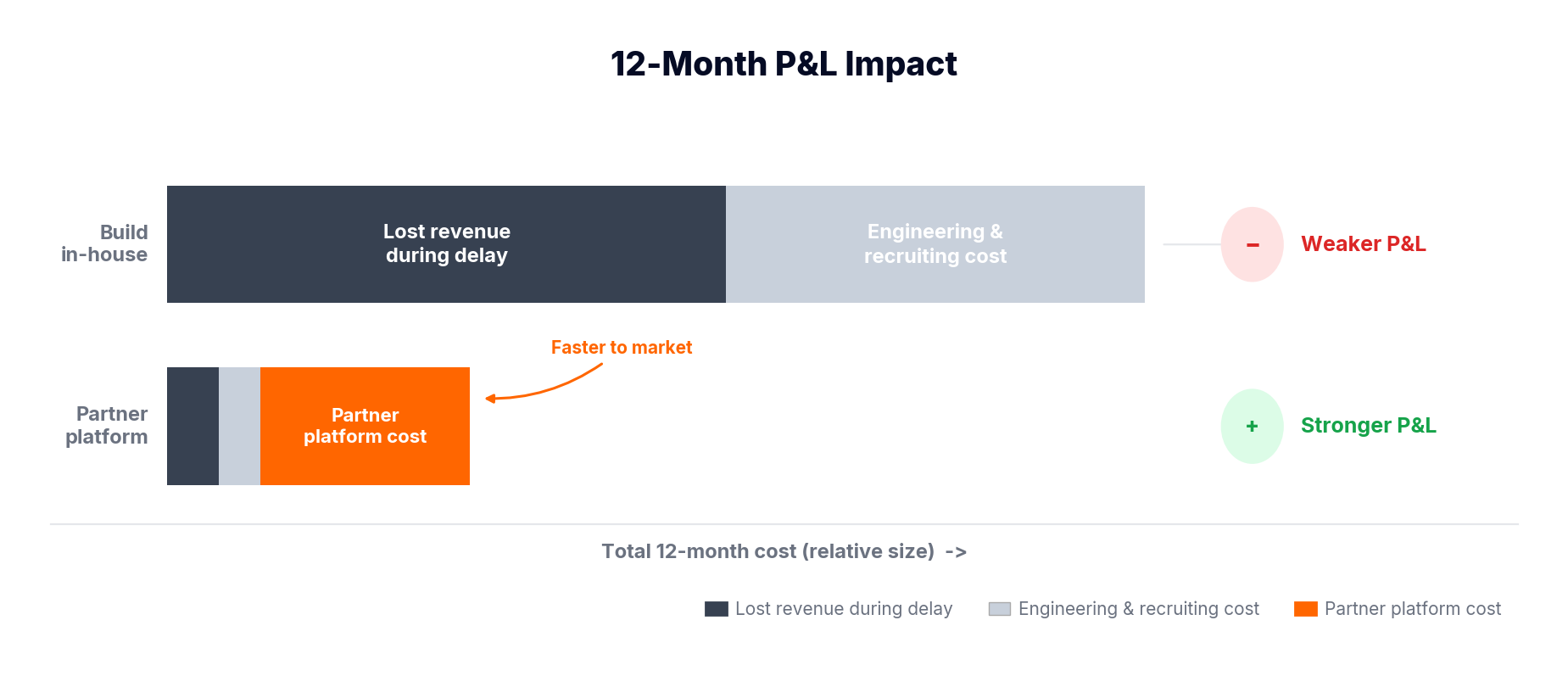
By contrast, a partner-led launch:
With all these, to capture peak asset value now vs. monetize a depreciated asset later while paying to build undifferentiated infrastructure.
Enterprise buyers do not purchase raw infrastructure. They evaluate confidence. From day one they expect a short checklist of production grade capabilities:
If you do not present evidence of all the above, the deal stalls. These items are not optional, and each one requires engineering effort and operational discipline.
Enterprise trust is a direct revenue variable: a single lost deal due to gaps in identity, isolation, or upgrade behavior can mean millions in ARR that never closes. Missed or vague SLAs slow sales cycles, block security review, and raise churn risk, because customers cannot bet critical AI workloads on platforms that may not meet their performance and availability promises.
The more immature your platform, the more discount and contract concessions you must offer to compensate, eroding margin on every deal..
Partnering with a production ready managed Kubernetes platform like vCluster fundamentally reweighs the economics.
With vCluster, production readiness shifts from many months to a matter of weeks. In the Boost Run case, a full GPU-native managed Kubernetes platform was launched in under 45 days, with enterprise-ready multi-tenancy and isolation available from day one.
This acceleration enables earlier deal closure, faster onboarding, and shorter sales cycles. Providers are able to compete more effectively against hyperscalers because they can meet enterprise requirements immediately, rather than after a long build cycle.
Even modest acceleration has an outsized financial impact. Pulling forward revenue realization by six months on a $5M pipeline does not just improve cash flow, it allows providers to capture demand while pricing and margins are still near peak.
vCluster fundamentally improves how infrastructure is utilized by enabling multi-tenant virtual clusters on shared underlying resources. Instead of duplicating control planes and fragmenting capacity across many clusters, providers can consolidate workloads and allocate GPUs more efficiently.
This leads to significantly higher utilization and better bin-packing of expensive GPU resources. As a result, revenue per GPU increases while infrastructure overhead grows much more slowly.
The outcome is a shift from linear cost scaling to operating leverage, where each additional customer contributes disproportionately more revenue than cost.
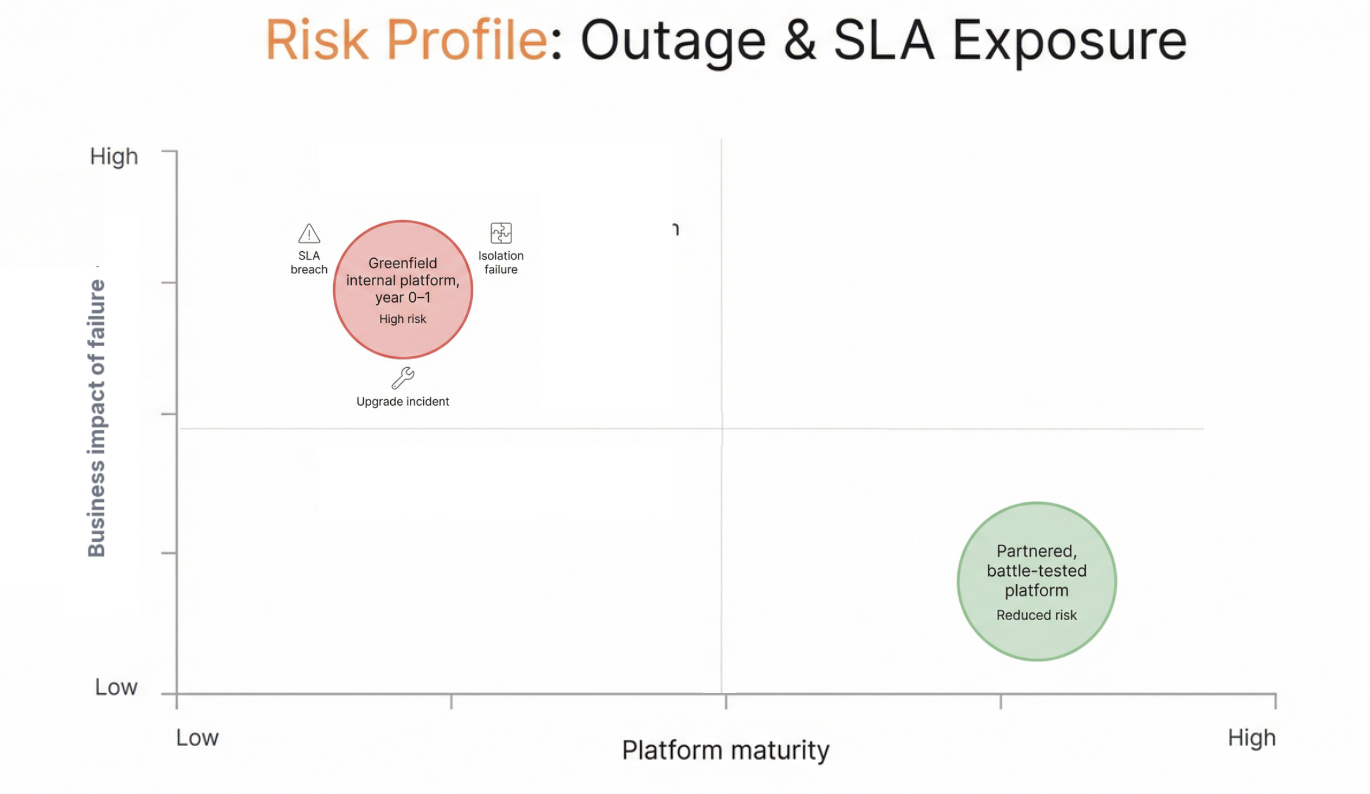
Building a production-grade Kubernetes platform internally introduces substantial operational risk, particularly around isolation, upgrades, networking, and failure recovery. These are complex systems that take time to mature and often fail under real-world load.
vCluster provides a battle-tested architecture with proven patterns for tenant isolation, centralized lifecycle management, and reliable operations. This reduces the likelihood of outages, security gaps, and performance instability.
From a financial perspective, this resilience protects revenue streams, preserves customer trust, and safeguards long-term pipeline. Reducing downside risk is economically equivalent to accelerating upside.
Partnering prevents the upfront staffing drag. Avoiding the recruitment and ramp for 4 to 6 senior platform engineers removes $1.0M to $2.1M in annual cost. Avoiding a larger 6 to 10 engineer program prevents $1.5M to $2.5M in annual burn. More important than the headline numbers is eliminating months of schedule risk tied to hiring and ramp.
Operational headcount also grows as tenant count increases. An internal model frequently assumes a fixed headcount to operate an initial set of tenants, but as each new customer arrives you often need additional SRE, support, and platform engineering resources. Partnering flattens that growth curve by absorbing platform operational scale, turning variable headcount into a far smaller incremental cost.
Use four core inputs: monthly GPU fleet value once monetized, expected revenue yield per GPU, internal build timeline, and fully loaded engineering and recruiting cost.
Calculate:
With vCluster the timeline compresses from 10 to 12 months to 4 to 6 weeks, engineering hiring requirements fall to near zero, and utilization improves through multi tenancy. These changes reduce both opportunity cost and operational overhead. In realistic scenarios the combined impact of avoided delay and reduced engineering spend exceeds partner cost by a wide margin, with payback measured in months rather than years.
Your durable advantage comes from work that directly improves revenue and differentiation:

Rebuilding Kubernetes control planes and multi tenant infrastructure does not create lasting competitive advantage. Hyperscalers already offer managed orchestration, and AI cloud providers who want to differentiate will do so above the orchestration layer. vCluster lets teams bypass undifferentiated platform plumbing and focus on differentiation that expands TAM and improves margins.
For executive buyers, this is fundamentally a capital allocation question: how much decaying asset value are you willing to sacrifice to build undifferentiated plumbing. This is not a technical architecture decision; it is a capital allocation decision: build and delay while a depreciating asset sits idle, or partner and capture value while your GPUs are still at peak.
If you choose to partner you move from planning to production in weeks, begin monetizing while hardware value is near peak, reduce operational and delivery risk, and free your best engineers to build revenue driving features. Frame the decision not as build versus buy, but as delay and dilute returns versus accelerate and capture value.
In GPU markets time is not neutral. Time is the dominant economic variable. Leaders who treat speed as a financial lever prioritize early revenue, protect asset value, and concentrate talent on what moves the business forward. The most expensive decision is choosing to wait.
Ready to shrink your in-house debt? Get a session here.
Deploy your first virtual cluster today.
