Guide
AI Cloud Buyer’s Guide to Kubernetes GPU Platforms
How to Evaluate Kubernetes Platforms for Building a Profitable Managed Kubernetes Service
AI Clouds are reshaping the AI infrastructure market. Across the industry, new GPU data centers are coming online at record speed. Tens of thousands of GPUs are being deployed to meet unprecedented demand for AI training, fine-tuning, and inference workloads.
In the first wave of this market, many GPU cloud providers were able to win customers simply by offering access to scarce hardware. Bare metal rentals, GPU VMs, and simple provisioning workflows were enough to stand out.
But the market is evolving quickly. Today, access to GPUs is no longer the primary differentiator. The differentiator is the platform experience delivered on top of GPU infrastructure.
Enterprise buyers increasingly expect Kubernetes as the standard interface for deploying and operating AI workloads. They want the ability to provision environments quickly, run production inference reliably, and support multiple teams with strong isolation guarantees. They want a service that feels comparable to hyperscaler offerings such as EKS, GKE, and AKS, except optimized for high-performance GPU infrastructure.
For AI Clouds, this shift creates a major opportunity. A well-architected managed Kubernetes offering expands the Total Addressable Market (TAM), increases customer retention, and enables higher-margin platform services beyond bare metal GPU rental.
However, it also creates a major risk. Building managed Kubernetes the wrong way leads to cluster sprawl, operational complexity, and an expensive platform engineering burden that scales linearly with customer growth.
This buyer’s guide is designed to help AI cloud and GPU infrastructure providers evaluate Kubernetes platforms, understand the architectural tradeoffs behind modern multi-tenant Kubernetes services, and avoid approaches that turn managed Kubernetes into a margin-killer rather than a growth engine.
The AI cloud ecosystem is maturing. Early adoption was driven by scarcity: customers needed GPUs, and they needed them quickly. Providers that could deliver capacity won deals even if customers had to manage their own software stack.
That dynamic is changing.
As AI becomes a core part of business operations, organizations are moving from experimentation to production. Multiple AI and ML teams are sharing infrastructure. Workloads are increasingly business-critical. Security and compliance requirements are tightening. Procurement teams are becoming involved. And platform engineering teams are insisting on Kubernetes as the standard operating model.
As a result, AI clouds are encountering a new category of customer expectation: buyers no longer just want infrastructure; they want a managed service.
Many AI clouds are now losing opportunities because customers require a more full-featured platform. The ability to offer managed Kubernetes is increasingly becoming a prerequisite for landing enterprise workloads.
This urgency is not just about meeting feature requirements. It is about differentiation and long-term competitive positioning.
Without a managed Kubernetes service, AI clouds are forced into a commodity pricing race. With a strong managed Kubernetes platform, Neoclouds can compete on experience, autonomy, security, and platform maturity.
In many ways, the AI cloud market is reaching the same inflection point that hyperscalers reached years ago: the winning providers will not simply offer compute, they will offer a platform.
An AI cloud-managed Kubernetes service must support a broad and fast-moving set of workload types. Modern AI workloads are diverse in lifecycle, performance profile, and isolation requirements, and customers expect the platform to accommodate all of them.
Training workloads are often long-running, distributed, and resource-intensive. They may involve multi-node orchestration, large-scale data ingestion, and specialized frameworks. Training jobs can run for hours or days, and interruptions are extremely costly. Customers running training workloads need predictable performance, stable runtime environments, and isolation from other tenants.
Inference workloads are typically latency-sensitive and production-facing. They require high availability, autoscaling, predictable networking performance, and clear uptime guarantees. Inference environments behave more like traditional production SaaS infrastructure, and they must be managed accordingly.
Many customers run fine-tuning, evaluation, and experimentation workloads that are short-lived and bursty. These workloads require rapid provisioning of GPU-enabled Kubernetes environments and the ability to scale up and down without friction. For these users, developer velocity and environment flexibility matter as much as raw performance.
As AI becomes more integrated into software delivery pipelines, teams increasingly require GPU-enabled environments for CI testing, model validation, and automated evaluation. These environments are typically ephemeral and need to be reproducible and easy to tear down.
In many cases, AI cloud customers are not just deploying workloads, they are deploying full AI platforms. This includes stacks such as Ray, Kubeflow, KServe, or custom orchestration layers. In these scenarios, customers need deep autonomy to configure Kubernetes components, install their own platform tooling, and manage their environment lifecycle independently.
An AI cloud-managed Kubernetes offering must assume that customer needs will evolve quickly. The platform must support a variety of workload profiles, multiple frameworks, and frequent changes in runtime configuration. A platform that is optimized for only one workload type will quickly become limiting.
Many Kubernetes platforms were designed to help enterprises manage their own clusters. AI clouds, however, are building a managed Kubernetes service that must scale operationally and commercially. This distinction changes what matters.
Many platforms treat the Kubernetes cluster as the primary unit of isolation. In this model, the easiest way to provide customer isolation is to provision a dedicated cluster per tenant.
While this approach provides clear separation, it leads directly to cluster sprawl. Every customer requires a control plane, cluster upgrades, monitoring stacks, logging stacks, and lifecycle management. As customer count grows, operational overhead grows linearly. GPU capacity becomes fragmented across clusters, leading to stranded resources where GPUs sit idle in one cluster while demand exists elsewhere.
For AI clouds, cluster-per-tenant models are rarely sustainable at scale.
Some platforms attempt to consolidate tenants into a shared Kubernetes cluster using namespaces. While namespaces provide logical separation, they do not provide the level of isolation that many enterprise customers require, especially for GPU workloads.
Namespace-based isolation depends heavily on policy enforcement, quotas, and correct configuration. Misconfiguration can lead to cross-tenant interference.
From the perspective of enterprise buyers, namespace-only multi-tenancy often feels like “shared infrastructure with guardrails,” not a true managed service boundary.
For AI clouds, perception matters. Even if policies are technically correct, buyers often want architectural isolation that is easy to understand and trust.
Platforms that rely on a shared Kubernetes control plane introduce upgrade coupling and operational risk. When tenants share a control plane, they cannot upgrade independently. Provider teams must coordinate changes across customers. Failures increase blast radius, and the provider becomes the bottleneck for tenant autonomy.
This is the opposite of what customers expect from a modern managed service.
GPU workloads are uniquely sensitive to runtime configuration, scheduling boundaries, and performance interference. Driver versions, CUDA runtimes, and GPU-specific components can differ between customers.
Platforms that cannot provide private or dynamically assigned GPU nodes per tenant force AI clouds into a difficult tradeoff: either allow unsafe sharing or over-provision infrastructure. Unsafe sharing increases risk and reduces enterprise trust. Over-provisioning reduces GPU utilization and harms margins.
AI clouds need node-level tenancy options as a core platform capability.
Some Kubernetes platforms rely heavily on admission policies, quotas, and manual governance to enforce safety. These approaches often scale poorly. As the number of tenants grows, the provider’s platform team becomes responsible for preventing misconfiguration and enforcing guardrails manually.
An AI cloud platform must reduce operational burden through architectural isolation rather than continuous intervention.
Many Kubernetes platforms assume networking isolation is handled externally or can be addressed through in-cluster constructs such as Kubernetes NetworkPolicies. For AI clouds, this is insufficient.
When delivering managed Kubernetes to external customers, networking is not an implementation detail, it is the trust boundary of the service. Enterprise buyers want to understand how traffic is segmented, how tenant boundaries are enforced at the infrastructure layer, and how blast radius is contained.
Platforms that do not integrate with purpose-built AI cloud networking stacks often struggle to provide enterprise-grade isolation guarantees without significant custom engineering.
A modern Kubernetes platform for AI clouds is not defined by a single feature. It is defined by architectural principles that determine whether managed Kubernetes can be delivered profitably, securely, and at scale.
AI clouds need to provide customers with isolated Kubernetes environments without provisioning a dedicated physical cluster for each tenant. The platform should allow each customer to run their own Kubernetes control plane with independent lifecycle management and upgrade flexibility.
This decoupling is critical for scaling managed Kubernetes without creating cluster sprawl.
AI clouds customers have different requirements. Some may accept shared infrastructure at lower cost. Others require strict isolation for compliance, security, or production stability.
A modern platform must support multiple tenancy models, enabling AI clouds to offer differentiated service tiers. This includes shared tenancy for entry-level offerings, private node tenancy for enterprise workloads, and dedicated environments where required.
This flexibility expands TAM while preserving efficient utilization of expensive GPU infrastructure.
For GPU workloads, node-level isolation must be built into the platform. The platform should support private GPU node pools per tenant, clear scheduling boundaries, and predictable performance characteristics.
This enables AI clouds to provide enterprise-grade isolation guarantees while still allowing shared infrastructure efficiency where appropriate.
GPUs are capital-intensive assets. Profitability depends on utilization.
An AI Cloud Kubernetes platform must support dynamic scaling and automated node assignment so that GPU capacity can be allocated where it is needed and reclaimed when it is idle. The platform should make it possible to scale tenant environments up and down without forcing operators to manually provision and manage GPU clusters.
Without elasticity, AI cloud risk stranded capacity and reduced margins.
Launching managed Kubernetes should not require building an internal hyperscaler team.
The platform must support automated tenant lifecycle management, consistent provisioning workflows, and operational simplicity. AI clouds should be able to onboard new customers quickly and support growth without hiring a large platform engineering organization.
The goal is to productize Kubernetes, not to create an ongoing engineering project.
For AI clouds, multi-tenancy is not only a Kubernetes problem—it is a networking problem.
Enterprise customers expect strong segmentation at the infrastructure layer. They want confidence that tenant environments are isolated not only within Kubernetes but also across networking and routing boundaries.
A platform must integrate with purpose-built networking stacks that support tenant-level segmentation, predictable connectivity models, and scalable isolation across many environments. Without this, AI Clouds struggle to deliver the security guarantees required for enterprise adoption.
The following questions help AI Clouds evaluate whether a Kubernetes platform can support a scalable managed Kubernetes offering.

Broadly, Kubernetes platforms for AI Clouds fall into two categories.
Many platforms focus on managing clusters and enforcing policy. These solutions treat the Kubernetes cluster as the unit of isolation. While they may provide strong cluster lifecycle tooling, they often require AI clouds to provision many physical clusters as customer count grows.
This approach leads to cluster sprawl, fragmented GPU capacity, and high operational overhead.
An alternative approach is to virtualize Kubernetes itself. In this model, Kubernetes control planes are decoupled from the underlying GPU infrastructure. Each customer receives an isolated Kubernetes control plane, while the provider maintains shared infrastructure efficiency.
This approach allows AI clouds to offer a managed Kubernetes service that feels like a dedicated cluster per customer, without duplicating the operational cost of running full clusters at scale.
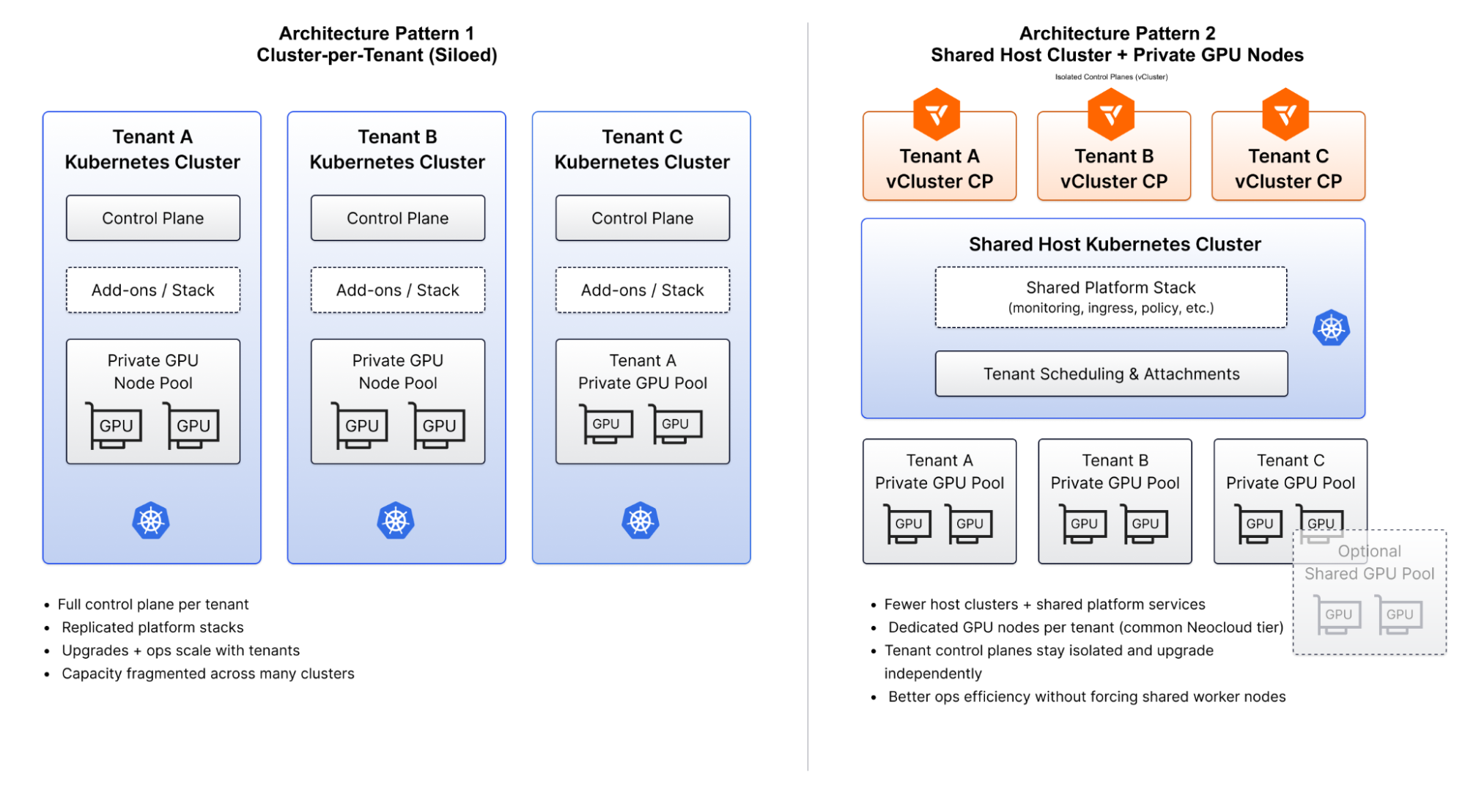
vCluster is designed around the idea that Kubernetes itself should be the unit of tenancy. For AI Clouds, this is a foundational advantage because it enables them to deliver a true managed Kubernetes service experience without the operational overhead and cluster sprawl of traditional approaches.
Rather than forcing providers to provision a full physical cluster per customer, vCluster allows AI clouds to offer isolated Kubernetes environments at scale on shared GPU infrastructure.
vCluster enables AI clouds to deliver isolated Kubernetes control planes per tenant. This gives customers the experience of a dedicated Kubernetes cluster, including independent lifecycle management, without requiring a dedicated physical cluster for every customer.
This architectural model is critical for AI clouds because it avoids cluster sprawl while maintaining strong isolation boundaries.
AI Clouds customers increasingly expect a managed Kubernetes experience that feels comparable to hyperscaler offerings. vCluster allows providers to deliver that experience while still pooling and allocating expensive GPU resources efficiently across many tenants.
This makes it possible to scale a managed Kubernetes service without fragmenting GPU capacity or sacrificing operational simplicity.
vCluster supports multiple tenancy models, including private node tenancy for GPU workloads. This allows AI clouds to offer differentiated service tiers, such as shared entry-level environments and enterprise-grade isolated environments.
As a result, providers can expand TAM and support a wider range of customer requirements without redesigning their platform architecture for each segment.
AI clouds buyers often evaluate managed Kubernetes offerings based on their ability to enforce isolation at the infrastructure layer, not just within Kubernetes.
Through deep networking integrations, including purpose-built AI clouds networking stacks such as Netris, vCluster enables hard multi-tenancy that extends beyond the Kubernetes control plane. This ensures that tenant isolation can be enforced not only at the control plane and node level, but also across infrastructure networking boundaries.
Managed Kubernetes is often perceived as expensive to operate because traditional architectures require a growing fleet of clusters and constant operational intervention.
vCluster’s approach significantly reduces that burden. Instead of requiring AI clouds to hire large platform engineering teams to manage cluster sprawl, vCluster provides a scalable foundation for automation, lifecycle management, and repeatable customer onboarding.
AI clouds are entering the next phase of the GPU infrastructure market. In the early days, success was driven by GPU access and pricing. Today, success is increasingly driven by platform maturity and customer experience.
Enterprise buyers expect Kubernetes as the standard interface for AI infrastructure, and AI clouds that cannot offer a scalable managed Kubernetes service risk losing larger opportunities to providers that can.
However, managed Kubernetes is not simply a feature to bolt on. It is a long-term architectural decision that determines whether a AI cloud can scale profitably.
Platforms built around cluster-per-tenant models, namespace-only multi-tenancy, or policy-heavy isolation approaches struggle to scale. They lead to cluster sprawl, fragmented GPU utilization, and rising operational overhead.
In contrast, platforms that virtualize Kubernetes control planes, support node-level isolation, enable elastic GPU capacity allocation, and integrate with AI cloud networking stacks allow providers to offer a managed Kubernetes service that is secure, scalable, and commercially flexible.
For AI Clouds looking to expand TAM, increase customer retention, and deliver an enterprise-grade Kubernetes experience on GPU infrastructure, the right platform architecture is the difference between a profitable managed service and an operational liability.
Deploy your first virtual cluster today.
