How vCluster Helps You Meet ClusterMAX™ Kubernetes Expectations
Delivering Managed Kubernetes for AI Cloud Providers
1. Executive Summary: Why AI Cloud Providers Choose vCluster
AI Cloud providers, companies building modern GPU accelerated infrastructure for AI workloads, are rapidly discovering that customers expect far more than raw compute. AI engineering teams want an experience similar to leading hyperscalers: Kubernetes clusters they can control, predictable performance, secure isolation from other tenants, and compatibility with the full modern ML ecosystem.
The ClusterMAX Kubernetes Expectations framework captures these requirements clearly. It defines the capabilities that enterprises assume a AI cloud should provide, including reliable Kubernetes access, strong isolation, GPU operator compatibility, NCCL performance, distributed training support, and cloud grade observability.
Building a managed Kubernetes offering that meets these expectations traditionally requires deep engineering investment. Most providers end up deploying a separate physical cluster per customer, a pattern that is slow, expensive, and operationally complex.
vCluster provides a more efficient path.
By virtualizing the Kubernetes control plane, vCluster allows AI Cloud providers to give every customer a dedicated Kubernetes cluster that behaves exactly like a cloud managed offering while running on a shared, high performance GPU fleet.
The result is a Kubernetes experience that aligns with ClusterMAX expectations, supports modern AI workloads, and avoids the cost and complexity of operating dozens of physical clusters.
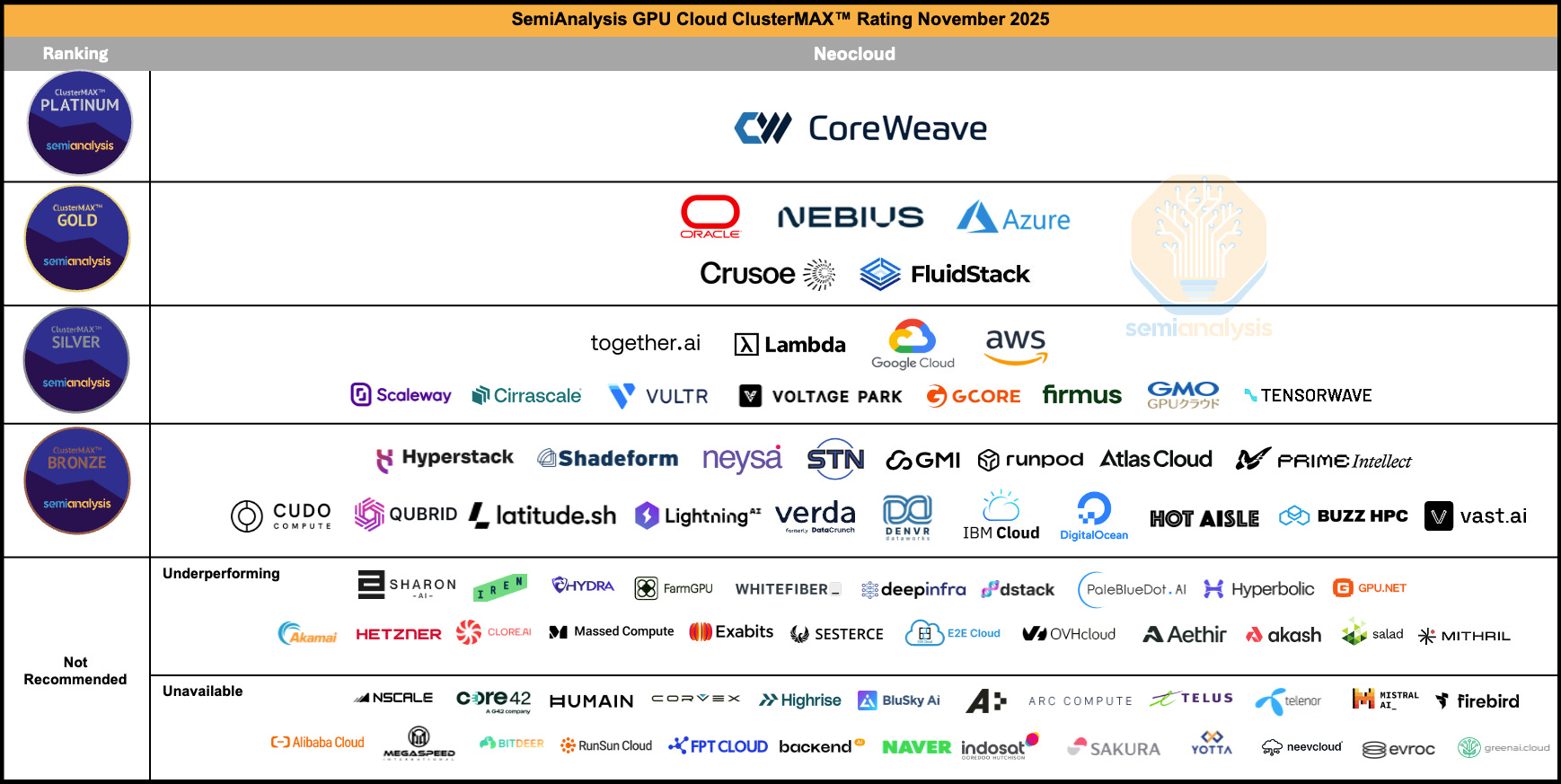
2. What Is ClusterMAX and Why It Matters
In the ClusterMAX framework, these modern cloud infrastructure providers are referred to as AI clouds, a broad category that includes both established AI cloud providers and emerging platforms aiming to deliver higher level services such as managed Kubernetes.
ClusterMAX, created by SemiAnalysis, is becoming a standard reference for comparing AI cloud providers. It evaluates many aspects of cloud infrastructure, including accelerators, networking, and data center design, but its Kubernetes category has become especially important because Kubernetes is the default interface for AI training, fine tuning, and inference workloads.
When evaluating a new AI cloud, enterprise customers frequently ask:
Can I get a secure, isolated Kubernetes cluster?
Does your cluster support GPU Operator, NCCL, and distributed training?
Is storage reliable and compatible with my workloads?
Will my ML jobs behave the same way they do on EKS or GKE?
ClusterMAX provides a consistent way to answer these questions. Providers who align with its Kubernetes expectations demonstrate enterprise grade readiness, GPU aware Kubernetes, AI workload compatibility, and operational maturity.
vCluster enables AI cloud providers to meet these expectations quickly without managing a large fleet of physical clusters.
3. How vCluster Enables Managed Kubernetes Offerings for AI Cloud Providers
AI Cloud providers need a Kubernetes experience that behaves like EKS, GKE, or AKS but is optimized for high performance GPU workloads. vCluster enables this through three architectural pillars.
3.1 Fully Isolated Kubernetes Clusters for Every Customer
Every vCluster is a dedicated Kubernetes control plane with:
Its own API server
Its own RBAC and authentication
Its own CRDs, operators, and controllers
Its own upgrade lifecycle
This gives each tenant the autonomy and predictability of a physical cluster without forcing providers to operate one actual cluster per customer. Control plane isolation is central to ClusterMAX’s multi tenancy expectations and is essential for AI and ML teams migrating from hyperscalers.
3.2 Native Integration With GPU Infrastructure and AI Workloads
vCluster virtualizes only the control plane. Workloads run directly on the provider’s GPU nodes, which means:
GPU Operator installs and functions as expected
CUDA, NCCL, MIG, and GPU topology behave normally
HPC networking and Network Operator work correctly when using Private Nodes
Distributed AI workloads like MPI, TorchElastic, Ray, and JAX perform as they would on a native cluster
No overhead is added to GPU scheduling or GPU data paths
Compatibility with the GPU stack is essential for meeting the GPU specific criteria in ClusterMAX.
3.3 Flexible Data Plane Isolation: Private Nodes, Auto Nodes, and Standalone Clusters
GPU workloads require careful isolation. vCluster provides three models that allow providers to offer strong multi tenancy without recommending shared nodes for GPU use.
Private Nodes
A tenant’s vCluster runs on exclusive GPU nodes. Ideal for:
Enterprise AI workloads
Multi node distributed training
Customers requiring predictable performance or isolation guarantees
Auto Nodes
Nodes are assigned to vClusters from a shared GPU pool as needed. Ideal for:
Startups and research workloads
Elastic GPU consumption
Lower cost Kubernetes tiers with real isolation
vCluster Standalone
A fully independent Kubernetes cluster for the tenant, both control plane and data plane, managed with the same automation.
Ideal for regulated enterprises or customers who need absolute separation.
These models enable providers to deliver an EKS like managed Kubernetes product optimized for GPU economics.
4. Full Mapping Table: ClusterMAX Criteria and How vCluster Meets Them
Core Kubernetes Configuration Requirements
ClusterMax Kubernetes Criteria
How vCluster Meets or Integrates
Cluster Access and Authentication
✔ vCluster behaves like upstream Kubernetes and integrates with host identity systems.
Kubeconfig simple download or properly configured
✔ Each vCluster provides its own kubeconfig with isolated authentication.
RBAC options with remote SSO provider integration
✔ Native SSO and OIDC support with per project RBAC.
Helm access available without custom external work
✔ Fully compatible with Helm using standard kubeconfigs.
Storage and Networking
ClusterMax Kubernetes Criteria
How vCluster Meets or Integrates
Default storage class configured and functional
✔ Inherits host CSI storage classes.
PVCs provision without hanging for helm charts and operators
✔ Matches host CSI behavior and provisions reliably.
Host path storage option available for model checkpoints
✔ Supported on Private Nodes with local NVMe or SSD.
CSI with ReadWriteMany support implemented
✔ Supported whenever RWX is available from host CSI.
Ingress, egress properly configured for secure, stable access
✔ Works with standard ingress controllers and Gateway API.
MetalLB or external load balancer available for services
✔ Compatible with MetalLB and cloud LBs.
GPU and Compute Infrastructure
ClusterMax Kubernetes Criteria
How vCluster Meets or Integrates
GPU Operator installed and up to date
✔ GPU Operator installs normally inside each vCluster.
Network Operator installed and configured
✔ Fully supported when using Private Nodes.
MPI Operator deployed for distributed workloads
✔ Behaves like native K8s and supports multi node training.
NCCL tests achieve full bandwidth performance
✔ Achieves native bandwidth on Private or Dedicated Nodes.
AI and ML Workload Support
ClusterMax Kubernetes Criteria
How vCluster Meets or Integrates
TorchTitan Llama 3.1 8B pretraining on C4 achieves equivalent throughput
✔ GPU Operator, CUDA, and NCCL stack operate normally.
LLM-D or SGL OME installation and operation
✔ Operators and CRDs deploy as expected.
Support for standard AI and ML frameworks and workloads
✔ Supports PyTorchJob, TensorFlow, JAX, Ray, KServe, Kubeflow and more.
GPU Specific Kubernetes Features
ClusterMax Kubernetes Criteria
How vCluster Meets or Integrates
MIG (Multi Instance GPU) support implemented
✔ MIG partitions exposed through host device plugins.
Fractional GPU scheduling available
✔ Fully supported with MIG.
Topology Manager functional
✔ Works correctly with Private or Standalone Nodes.
NUMA awareness for GPU affinity
✔ NUMA topology preserved.
NVIDIA DCGM integration
✔ DCGM exporter integrates with Prometheus and Grafana.
GPU driver version consistency
✔ Ensured through GPU Operator and node image lifecycle.
Networking, Ingress, and Traffic Management
ClusterMax Kubernetes Criteria
How vCluster Meets or Integrates
Network policy enforcement functional
✔ Enforced by host CNI.
Ingress controller optimization
✔ Compatible with NGINX, Contour, HAProxy, Traefik and others.
eBPF based networking supported
✔ Fully supported when using Cilium or similar CNI.
Integration Requirements
ClusterMax Kubernetes Criteria
How vCluster Meets or Integrates
Integration with comprehensive health check systems
✔ Compatible with Kubernetes native and external systems.
Integration with monitoring systems, Kube prometheus, Grafana
✔ Works with Prometheus, Grafana, Alertmanager, DCGM exporters.
Node Problem Detector deployed
✔ Fully compatible at the host level.
Draino for automated node management
✔ Supported, correct eviction behavior preserved.
Standard Installation Components
ClusterMax Kubernetes Criteria
How vCluster Meets or Integrates
Cilium for networking
✔ Fully compatible with Cilium or any host CNI.
GPU Operator for GPU management
✔ Fully supported.
Network Operator for high performance networking
✔ Supported when nodes are isolated.
RWX storage
✔ Works whenever the host CSI supports RWX.
Node resource quotas implemented
✔ vCluster enforces tenant specific quotas.
Cluster autoscaler available
✔ Compatible with eviction and scheduling behavior.
Kube prometheus stack installed
✔ Fully supported inside vClusters.
Support and Operations
ClusterMax Kubernetes Criteria
How vCluster Meets or Integrates
Managed service support available
✔ Supported through vCluster enterprise support.
Security patches and CVE response
✔ Follows vCluster security advisory processes.
Monitoring and alerting integrations
✔ Integrates with Prometheus, Grafana, Alertmanager, cloud monitoring.
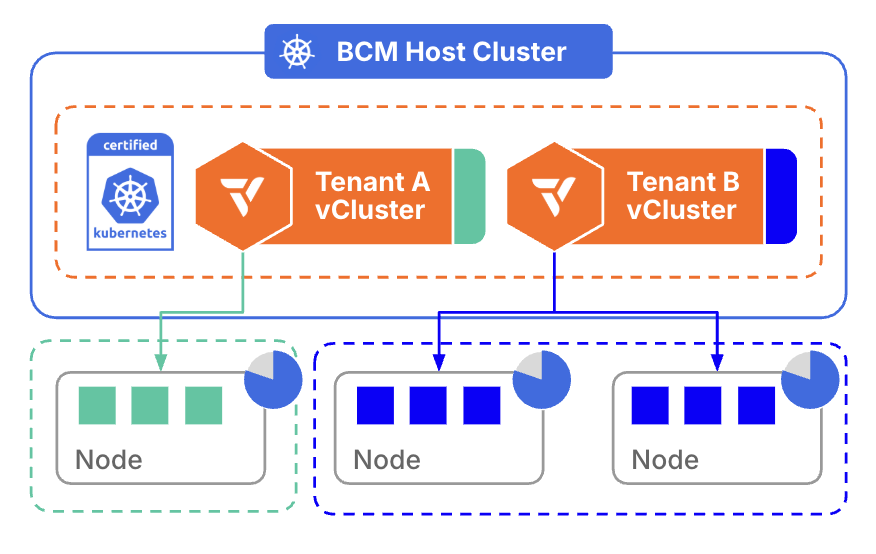
5. Architecture Overview: How vCluster Supports a Managed Service
A typical AI cloud built on vCluster includes:
The Host GPU Cluster
High performance GPU nodes, HPC networking, CSI storage, observability stacks, and node lifecycle automation.
vCluster Platform
Multi tenancy management, templates, RBAC and SSO integration, lifecycle automation, upgrades, and provisioning logic.
Tenant vClusters
Each customer receives their own isolated Kubernetes control plane with the ability to install operators and tools without affecting others.
This architecture combines isolation, efficiency, and performance consistency into a unified managed Kubernetes experience.
6. Benefits for AI Cloud Providers
Delivering a managed Kubernetes service is essential for AI clouds that want to attract enterprise AI workloads or improve their position in the ClusterMAX rankings. vCluster provides the missing control plane and multi tenancy layer that allows providers to differentiate on platform capability rather than simply hardware availability. By virtualizing the Kubernetes control plane, vCluster enables AI clouds to move up the value chain, strengthen their competitive position, and deliver a more complete cloud experience to customers.
6.1 Faster Time to Market
AI clouds can introduce a fully managed Kubernetes offering in less time than it would take to build one internally.
vCluster removes the need to develop complex control plane automation and multi tenant logic.
Providers deliver an EKS like cluster experience without hyperscaler scale or engineering resources.
This accelerates platform expansion and shortens the path to new customer revenue.
Below are the key advantages that vCluster unlocks for AI cloud providers.
6.2 Strong Isolation Without Extra Clusters
Control plane isolation gives each customer a dedicated Kubernetes environment while avoiding cluster sprawl.
Tenants experience a real cluster, not a namespace partition.
Private Nodes and Auto Nodes provide data plane isolation without deploying a new physical cluster.
This keeps operations simpler and more cost efficient.
6.3 AI Ready Kubernetes
For AI teams, predictability and compatibility matter as much as performance.
GPU Operator, NCCL, MIG, and distributed training work natively inside vClusters.
Customers migrate workloads from EKS, GKE, or on premises environments with no refactoring.
This improves adoption and reduces migration friction.
6.4 Operational Efficiency at Scale
vCluster centralizes Kubernetes complexity so providers can scale their services efficiently.
Many vClusters can coexist on a single host cluster.
Monitoring, upgrades, and policy enforcement remain unified.
Providers avoid maintaining dozens or hundreds of standalone clusters.
This reduces infrastructure overhead and simplifies long term operations.
6.5 Better Alignment With ClusterMAX Expectations
ClusterMAX rewards AI clouds that invest in their Kubernetes layer.
vCluster satisfies multi tenancy, GPU readiness, observability, and operational requirements.
Providers advance their ClusterMAX standing by delivering a modern managed Kubernetes offering.
This elevates platform credibility and increases customer trust.
7. Deliver the Managed Kubernetes Layer That Elevates Your ClusterMAX Rating
Many AI cloud providers find that their ClusterMAX ranking is limited not by hardware or networking, but by the absence of a true managed Kubernetes layer. ClusterMAX rewards platforms that provide isolated control planes, reliable Kubernetes behavior, GPU operator maturity, NCCL performance, and enterprise grade tenant boundaries.
vCluster gives providers a fast and proven way to deliver this layer.
By virtualizing the control plane, providers can offer each customer a fully isolated, upstream compatible Kubernetes cluster that supports GPU Operator, distributed AI workloads, and all the operational features that ClusterMAX evaluates. Instead of managing dozens of physical clusters, providers run a unified GPU fleet and deliver the experience customers expect from a modern cloud provider.
If your goal is to rise in the ClusterMAX rankings, this is the most impactful advancement you can add to your platform.
See how vCluster can elevate your Kubernetes offering and strengthen your ClusterMAX position.