Guide
How vCluster Helps NVIDIA Cloud Partners Build Exemplar-Ready AI Clouds
A Practical Architecture Guide for AI Clouds
For NVIDIA Cloud Partners, access to GPUs is no longer enough.
As the AI cloud market matures, customers are evaluating providers based on operational discipline, performance predictability, benchmarking reproducibility, and platform maturity. NVIDIA’s Exemplar Cloud initiative reflects this shift. It highlights cloud providers that can deliver validated performance through structured benchmarking and consistent infrastructure design.
For many AI Clouds, the limiting factor in reaching Exemplar-level maturity is not hardware capacity. It is the Kubernetes platform architecture required to:
This guide outlines how vCluster, a virtual cluster technology that provides isolated Kubernetes control planes on shared infrastructure, enables NVIDIA Cloud Partners to implement the architectural patterns required for Exemplar-ready AI infrastructure.
Exemplar readiness is not achieved by tuning hardware alone. It is built into the structure of the platform.
While Exemplar status is evaluated through benchmarking frameworks, the providers that succeed share common architectural characteristics.
Exemplar-ready infrastructure typically delivers the following outcomes:
These are not isolated features. They are consequences of disciplined platform design.
Many emerging AI clouds start with a simple model:
New tenant, new Kubernetes cluster.
This is understandable. It is easy to reason about, it feels isolated, and it aligns with traditional managed Kubernetes assumptions.
However, as tenant count increases, cluster-per-tenant architectures create compounding challenges that directly impact Exemplar readiness. What begins as a straightforward delivery model quickly turns into an operational bottleneck that makes it difficult to scale efficiently, standardize environments, and deliver repeatable performance outcomes.
The result is a platform that becomes harder to operate, harder to benchmark consistently, and increasingly expensive to scale.
Every tenant adds another control plane, another upgrade cycle, another security posture, another set of policies, and another set of configurations.
Even a small NVIDIA Cloud Partner can quickly find themselves managing dozens of Kubernetes clusters, each requiring ongoing patching, observability, and operational maintenance.
Cluster sprawl introduces fragmentation into the platform. Platform teams must coordinate upgrades across environments, respond to incidents in clusters that behave differently, and maintain security posture across an expanding fleet.
For AI clouds pursuing Exemplar-grade maturity, cluster sprawl is not just a scaling inconvenience. It is an architectural limitation that directly impacts operational discipline and reproducibility.
Over time, each cluster becomes slightly different:
Even if clusters begin in a standardized state, they rarely remain that way. Tenant-specific requests, urgent fixes, and incremental upgrades introduce divergence.
Eventually, the platform becomes a collection of unique environments rather than a cohesive, standardized offering.
Benchmarking results become inconsistent, not because the GPUs differ, but because the Kubernetes environments are no longer uniform.
For benchmarking initiatives such as NVIDIA Exemplar Clouds, this drift introduces uncertainty. It becomes difficult to validate and reproduce performance results confidently when the underlying platform varies across environments.
Cluster-per-tenant architectures often force dedicated GPU pools, even when tenant demand fluctuates.
This leads to:
To guarantee isolation and performance, providers frequently over-provision GPU capacity. While this may simplify isolation logic, it reduces platform efficiency and increases cost.
For NVIDIA Cloud Partners, GPU utilization is a primary economic lever. Idle GPUs represent not only wasted capacity but also diminished competitiveness in a market where pricing and performance transparency are increasing.
Exemplar-ready platforms must support strong isolation while still enabling efficient resource sharing and workload consolidation.
Each additional cluster increases:
Operational cost begins to scale linearly with tenant growth.
Even if infrastructure capacity is available, platform teams eventually hit an operational ceiling. Upgrade cycles slow down, platform improvements become risky, and troubleshooting becomes more complex because each cluster behaves slightly differently.
This is often where emerging AI clouds struggle to compete with larger providers. Not because they lack GPUs, but because they cannot scale operational maturity at the same pace as customer growth.
If benchmarking environments require provisioning full clusters, teams often:
Benchmarking becomes a high-effort activity instead of a repeatable platform workflow.
This directly undermines the reproducibility that Exemplar readiness demands. Providers may achieve strong results in one cluster but struggle to replicate those results across different environments or configuration states.
To reach Exemplar-grade maturity, benchmarking must be standardized, repeatable, and scalable. That is difficult to achieve when every tenant environment requires its own dedicated physical cluster.
Cluster-per-tenant models are a natural starting point for many AI clouds. However, they introduce structural challenges that directly conflict with the outcomes Exemplar-grade infrastructure requires.
When tenant isolation depends on multiplying physical clusters, providers inherit drift, inefficiency, and operational overhead that scales faster than customer growth. Benchmarking becomes inconsistent, GPU utilization suffers, and platform maturity plateaus.
To achieve Exemplar-level readiness, NVIDIA Cloud Partners need a model that preserves tenant isolation without multiplying clusters.
The solution is not more clusters.
It is a different control plane architecture.
At a high level, vCluster enables virtual Kubernetes clusters, meaning multiple independent Kubernetes control planes can run on top of a shared underlying host cluster.
Instead of provisioning a full physical cluster per tenant, the provider runs a shared host cluster and creates a vCluster for each tenant.

This architecture enables a cloud provider to deliver:
In practice, vCluster becomes the Kubernetes platform layer that allows an NCP to scale without multiplying clusters.
Exemplar readiness is not defined by a single benchmark run. It is defined by whether a cloud platform can deliver performance predictably, repeatedly, and at scale.
For NVIDIA Cloud Partners, the challenge is not only achieving strong performance, but building an architecture that can support many tenants, enforce consistent environments, and run repeatable benchmarking workflows without multiplying clusters and operational overhead.
The following architecture patterns represent the foundational building blocks of an Exemplar-ready AI cloud platform. Each pattern addresses a common scaling constraint for AI clouds and outlines how vCluster enables a more scalable approach to multi-tenant Kubernetes delivery.
Why This Matters
Isolation is a core requirement for enterprise AI workloads. AI cloud customers expect autonomy, predictable performance, and strong boundaries between tenants. In practice, that often means customers want their own Kubernetes API endpoint, their own RBAC model, and the ability to install custom tooling without interference.
The traditional approach is cluster-per-tenant. While effective for isolation, it becomes operationally expensive at scale. Each new tenant adds another control plane, another upgrade lifecycle, and another cluster footprint to manage.
The Scalable Pattern
Deliver tenant isolation at the control plane layer, not by multiplying physical clusters.
How vCluster Enables This Pattern
Architectural Outcome
vCluster allows NVIDIA Cloud Partners to offer a true Kubernetes experience per tenant without the operational cost of provisioning full clusters per customer. Tenant autonomy increases while cluster sprawl is reduced, enabling scalable multi-tenancy without sacrificing isolation.
Why This Matters
Benchmark reproducibility depends heavily on environment consistency. Many AI clouds see inconsistent benchmark results not because GPU infrastructure differs, but because Kubernetes environments drift over time.
Exemplar readiness requires benchmarking outcomes to remain repeatable across time, across environments, and across tenant deployments.
The Scalable Pattern
Standardize Kubernetes environments using repeatable, template-driven control planes.
How vCluster Enables This Pattern
vCluster enables golden templates that standardize:
Architectural Outcome
By controlling the Kubernetes layer, providers eliminate a major source of benchmark variability. Benchmarking becomes repeatable because the environment is repeatable.
Why This Matters
Benchmarking is often treated as a special event requiring manual provisioning and coordination. This approach does not scale.
Exemplar readiness requires benchmarking to be repeatable, automated, and isolated from production environments.
The Scalable Pattern
Treat benchmarking as an on-demand platform workflow using ephemeral environments.
How vCluster Enables This Pattern
Example workflow:
Architectural Outcome
Benchmarking becomes a repeatable operational capability rather than a coordinated event.
Why This Matters
GPU efficiency defines AI cloud economics. At the same time, AI workloads are sensitive to performance variability, and many customers require dedicated infrastructure.
Exemplar-grade providers must support predictable performance without sacrificing utilization.
The Scalable Pattern
Decouple tenant isolation from GPU allocation.
How vCluster Enables This Pattern
vCluster isolates control planes by default. Tenancy models define worker node allocation. Auto Nodes enables dynamic provisioning via built-in Karpenter.
Architectural Outcome
Dedicated and Private node pools provide predictable performance, while Auto Nodes ensures efficient scaling and utilization.
Why This Matters
NVIDIA Cloud Partners serve customers with varying isolation and compliance requirements. A scalable platform must support multiple isolation models without multiplying clusters.
The Scalable Pattern
Offer multiple worker node isolation models within a unified platform.
vCluster Tenancy Models
With Auto Nodes enabled, Dedicated and Private node pools scale dynamically based on demand.
Architectural Outcome
Providers can deliver tiered services without fragmenting infrastructure, increasing flexibility while maintaining operational consistency.
Why This Matters
Cluster-per-tenant models fragment governance. Each cluster becomes its own upgrade and security boundary.
Exemplar readiness requires consistent policy enforcement and predictable upgrade cycles.
The Scalable Pattern
Centralize platform governance while preserving tenant autonomy.
How vCluster Enables This Pattern
Architectural Outcome
Security posture and upgrades become consistent across tenants, improving operational maturity.
Why This Matters
Cluster-per-tenant models create linear growth in operational complexity. As tenant count increases, so does cluster count, upgrade workload, and support burden.
The Scalable Pattern
Increase tenant count without increasing cluster count at the same rate.
How vCluster Enables This Pattern
Architectural Outcome
Operational leverage improves as tenant environments remain isolated and standardized while the underlying infrastructure stays consolidated.
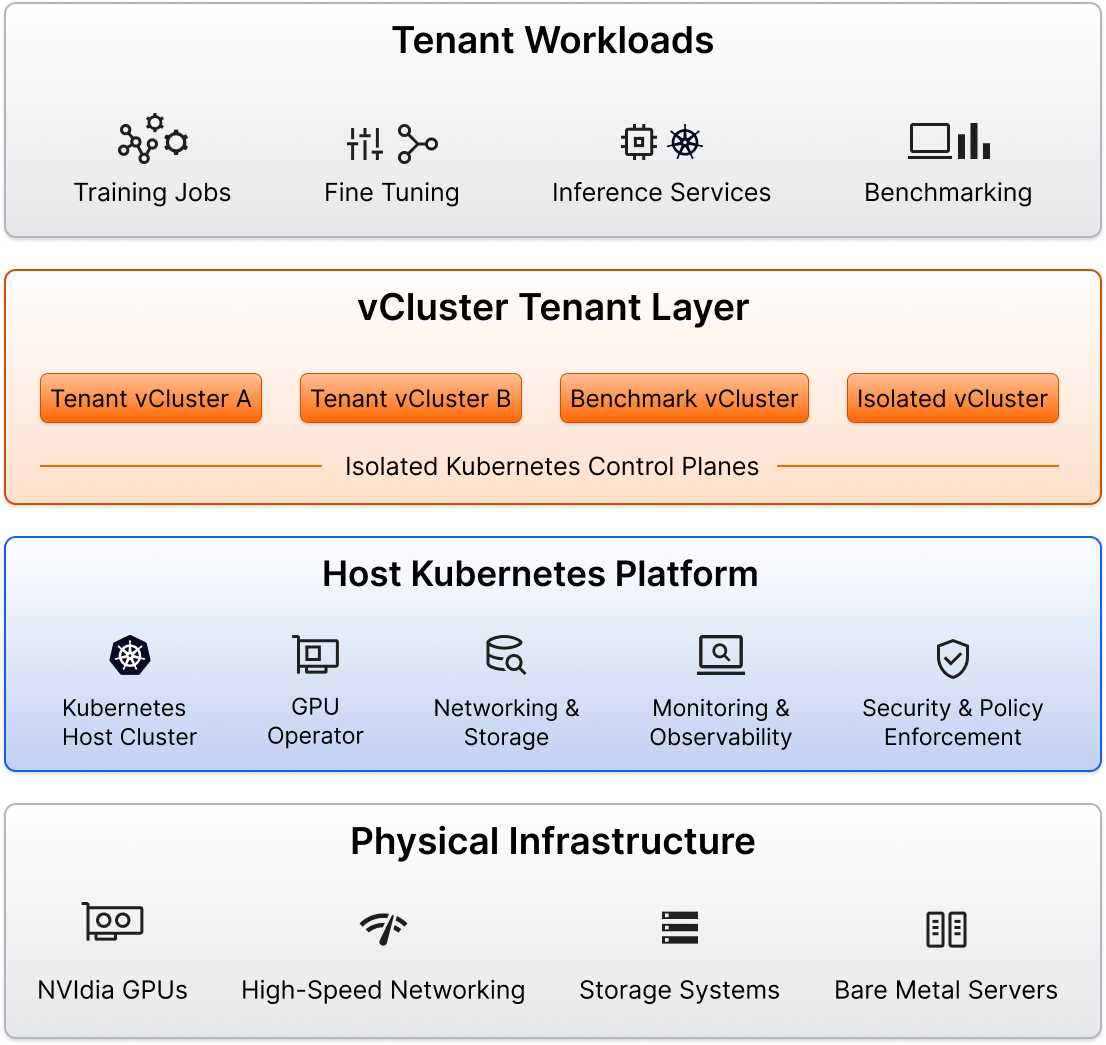
An Exemplar-ready AI cloud is structured as a layered stack.
This layer provides performance capacity but does not define platform maturity.
Operated by the NVIDIA Cloud Partner, this layer includes:
This layer ensures operational consistency.
Each tenant receives:
Multiple vClusters run on shared infrastructure, reducing cluster sprawl while preserving autonomy.
Tenants deploy:
This layered model enables reproducibility, consolidation, flexibility, and operational control.
Exemplar readiness emerges from this structured platform architecture.
Every NVIDIA Cloud Partner is at a different stage of maturity.
Some are early-stage AI clouds onboarding their first enterprise AI customers. Others are scaling rapidly and feeling operational strain. More mature providers are serving regulated industries and preparing for benchmarking validation.
Below is a progression model that maps platform evolution to recommended vCluster patterns.
At this stage, the focus is speed. The team is small, infrastructure is lean, and onboarding new customers quickly is critical. Operational simplicity matters more than complex isolation models.
Outcome:
Fast onboarding, minimal cluster sprawl, consistent Kubernetes environments from the start.
As customer count increases, operational complexity begins to surface.
Upgrades become heavier, tenant requirements diverge, and benchmarking workflows need more structure.
This is often where cluster-per-tenant models begin to break down.
Outcome:
Higher GPU utilization, reduced operational overhead, more predictable performance across tenants.
At this stage, the platform must support strict SLAs, enterprise security requirements, and potentially regulated workloads. Operational maturity becomes a competitive differentiator.
Providers at this level are often evaluating Exemplar validation or similar benchmarking initiatives.
Outcome:
Enterprise-ready platform maturity, scalable multi-tenancy, and architectural readiness for benchmarking validation programs such as Exemplar.
The key insight is that Exemplar readiness is not a binary state. It is a function of platform maturity.
AI clouds that adopt virtualized control plane architectures early can evolve naturally from Stage 1 to Stage 3 without rewriting their platform strategy or multiplying clusters at each growth phase.
vCluster provides a consistent architectural foundation across all three stages, allowing NVIDIA Cloud Partners to scale tenant count, benchmarking workflows, and operational maturity without scaling infrastructure complexity at the same rate.

Benchmarking
Isolation
GPU Efficiency
Standardization
Operational Scalability
If the answer to these questions is uncertain, the limitation is architectural.
vCluster provides a foundation for building scalable, reproducible, multi-tenant AI infrastructure aligned with Exemplar-level expectations.
NVIDIA’s Exemplar Cloud initiative reflects a broader shift in the AI infrastructure market. GPUs alone are no longer enough. Operational maturity, reproducibility, and scalable multi-tenancy are becoming the real differentiators.
Exemplar readiness is not achieved through last-minute performance tuning. It is the outcome of deliberate platform design. When tenant isolation depends on multiplying physical clusters, scalability eventually stalls. Drift accumulates, operational overhead increases, and benchmarking consistency suffers.
The architectural shift described in this guide moves isolation to the control plane layer. By consolidating physical infrastructure while delivering isolated Kubernetes environments per tenant, NVIDIA Cloud Partners can reduce cluster sprawl, standardize environments, improve GPU utilization, and scale operations without scaling complexity at the same rate.
vCluster enables this shift. It provides the virtualized control plane foundation that allows AI clouds to evolve from fragmented cluster fleets to consolidated, template-driven, multi-tenant AI platforms.
Exemplar status is not something added on top of infrastructure. It is built into the Kubernetes layer itself. For NVIDIA Cloud Partners looking to compete at the highest level of AI infrastructure delivery, virtual cluster architecture is a foundational step toward that maturity.
Deploy your first virtual cluster today.
