Guide
Scaling Kubernetes Adoption on AWS
Why EKS Alone Isn’t Enough and How to Avoid Re-Architecting Later
Most organizations do not struggle with starting Kubernetes. They struggle with what happens next.
The first Amazon EKS cluster typically launches without major friction. A focused team deploys production workloads, integrates CI/CD pipelines, connects observability, and demonstrates value. Kubernetes works. Confidence grows.
Then adoption spreads.
More teams request environments. Platform engineering is asked to standardize. Security begins reviewing isolation boundaries. Finance demands cost visibility. Compliance introduces new constraints. Autonomy becomes a recurring requirement.
At this stage, the challenge is no longer how to run Kubernetes. The challenge is how to deliver Kubernetes as a scalable internal platform service, without multiplying infrastructure, operational burden, or organizational friction.
For organizations that are still largely VM-based but steadily increasing Kubernetes adoption on AWS, this is the architectural inflection point. The decisions made here determine whether Kubernetes becomes a durable foundation or a recurring re-architecture project.
Running Kubernetes for one team is a technical challenge. Running Kubernetes for dozens of teams is an organizational one. As adoption increases, platform teams encounter predictable pressure:

These pressures are not signs of failure. They are signs that Kubernetes is becoming central to the organization.
The architectural question becomes unavoidable:
Where should the isolation boundary live?
When enterprises increase Kubernetes adoption on AWS, they usually converge on one of four architectural models. Each emerges from a reasonable goal: simplicity, isolation, consolidation, or autonomy.
The difficulty is not that these models are wrong. It is that each optimizes for one dimension while creating pressure in another. Understanding those tradeoffs clearly is what prevents reactive re-architecture later. In most organizations, these approaches work initially until growth forces a redesign. That redesign is what most teams experience as “Kubernetes becoming hard.”
For organizations early in their container journey, especially those still largely VM-based, Kubernetes can feel like a significant operational leap. In AWS environments, that often leads teams to evaluate Amazon ECS as a simpler alternative.
ECS provides a managed container orchestration experience tightly integrated with AWS primitives. For teams primarily focused on running containerized workloads without building a Kubernetes-native platform, this can be appealing.
ECS can be entirely appropriate when the goal is container deployment without platform abstraction. However, as organizations begin adopting CRDs, operators, GitOps workflows, policy engines, and service meshes, ecosystem gravity pulls toward Kubernetes. At that point, moving from ECS to Kubernetes is rarely a lift-and-shift exercise.
ECS simplifies early adoption. It may constrain long-term flexibility.
When Kubernetes adoption accelerates, the most straightforward way to provide isolation is to provision an EKS cluster per team. This approach feels structurally clean and avoids many of the coordination issues found in shared environments.
Each team benefits from strong autonomy and clear boundaries.
At smaller scales, this model works extremely well. The challenge appears gradually. Each additional team means another control plane to secure, upgrade, monitor, and govern. Over time, cost and operational overhead scale with organizational structure rather than workload demand.
Cluster-per-team architectures optimize for isolation clarity. They often sacrifice infrastructure efficiency and long-term operational simplicity.
In response to cluster sprawl, platform teams often consolidate workloads into a shared EKS cluster and allocate namespaces per team. The motivation is rational: reduce duplicated control planes and centralize governance.
From an infrastructure perspective, this model improves efficiency.
Shared clusters reduce infrastructure fragmentation, but they shift complexity upward. Since CRDs are cluster-scoped, teams can interfere with one another unintentionally. Granting cluster-admin privileges becomes risky. Platform teams often become bottlenecks for changes that require elevated permissions.
Consolidation solves cost duplication. It introduces coordination friction and autonomy constraints.
All three models above share a foundational assumption: the cluster is the isolation boundary.
When that assumption holds, organizations are forced into tradeoffs. They either multiply clusters to increase isolation, or they consolidate into shared clusters and accept governance complexity and coordination risk.
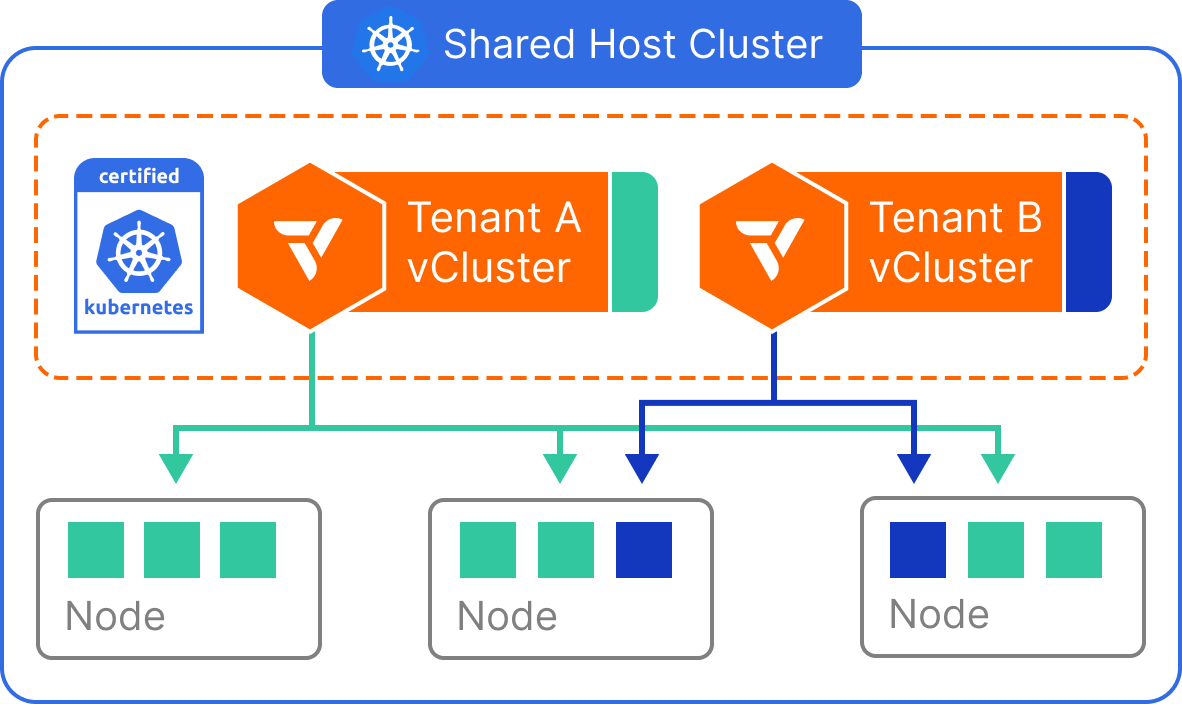
A control-plane isolation model changes that equation by separating infrastructure consolidation from Kubernetes API isolation.
Instead of treating the cluster as the unit of tenancy, the control plane becomes the unit of isolation. Teams interact with isolated Kubernetes control planes while sharing a common infrastructure substrate underneath.
This is where virtual clusters come in.
With vCluster, each team operates within its own Kubernetes control plane, complete with its own API server and isolated Kubernetes objects. Underneath, workloads can run on shared nodes for efficiency or on private node pools for stronger workload separation.
The architectural shift is subtle but significant. The cluster is no longer the unit of isolation. The control plane is. Once isolation is decoupled from infrastructure, organizations no longer have to choose between cost efficiency and autonomy.
This is what prevents the common enterprise re-architecture cycle: starting with namespaces in a shared cluster, moving to cluster-per-team when autonomy and CRD conflicts become unmanageable, and then rebuilding again when cluster sprawl becomes too expensive to sustain.
By shifting the isolation boundary to the control plane, organizations can scale adoption without repeatedly changing the underlying platform model.
The goal is not to identify a universal winner, but to evaluate which model remains stable as Kubernetes adoption expands.
Enterprise platforms rarely require a single isolation model for every workload. Development and testing environments optimize for speed and cost efficiency, while production and regulated workloads optimize for predictability and stronger separation. If the platform forces you to pick one model globally, you often end up re-architecting later as requirements tighten.
A more durable approach is progressive tenancy: keep the same tenancy abstraction for teams, and adjust only the infrastructure allocation beneath it as you move from non-production to production.
In practice, that progression typically starts with shared nodes and expands to private nodes.This is the key advantage of progressive tenancy: you can evolve from dev/test consolidation to production-grade isolation without changing the platform architecture.
Shared nodes are often the best starting point because they remove two of the biggest early adoption friction points: cost and operational overhead. Instead of provisioning a separate EKS cluster per team or per environment, teams run workloads on a shared worker substrate while interacting with isolated control planes.
The key idea is that teams get the experience of “their own Kubernetes” without requiring “their own cluster.”
This model is most effective for environments that are high-churn and cost sensitive, such as dev/test, preview environments, and CI workloads. These environments often sit idle for long periods, and that idle capacity becomes expensive when every team owns dedicated infrastructure.
Shared nodes are a strong fit for workloads where efficiency and fast iteration matter more than strict workload separation:
Shared nodes are designed to maximize consolidation and minimize waste. This model typically delivers:
As Kubernetes adoption expands into production and regulated workloads, some teams will require stronger isolation. Sometimes this is driven by compliance requirements. Other times it’s driven by performance sensitivity and the need to avoid noisy-neighbor effects. In many organizations, this is the moment where teams default to “cluster per team” because it seems like the only safe path forward.
Private nodes provide a cleaner progression.
Instead of provisioning a new EKS cluster for each team, the platform allocates dedicated node pools beneath the same tenancy abstraction. Teams still operate within isolated control planes, but their workloads land only on nodes reserved for them (or for a specific workload class).
The most important advantage is that you increase separation without changing how teams interact with Kubernetes. You are not migrating teams to a different platform model — you’re simply adjusting the resource allocation beneath the model they already use.

Private nodes are a natural fit when workload-level concerns become more important:
Private nodes are designed to increase workload isolation without forcing cluster sprawl. This model typically improves:
The platform trap many organizations fall into is treating isolation as a binary choice: either you share everything (namespaces) or you duplicate everything (cluster per team). Progressive tenancy creates a middle path that scales by aligning isolation strength with workload requirements without forcing platform redesign as needs evolve.
What makes this approach work in practice is that the tenancy abstraction remains stable even as the underlying infrastructure model changes. Teams do not need to adopt a completely different approach when they move from dev/test into production. Instead, they continue operating within the same isolation boundary while the platform team adjusts how infrastructure is allocated beneath them.
This is where vCluster’s flexibility becomes a strategic advantage.
vCluster supports a range of tenancy models — from shared nodes to private nodes and beyond — while preserving the same control plane abstraction for teams. That means you can start with one model early in the adoption journey and evolve to another as requirements change, without forcing teams into bottlenecks or disruptive migrations.
To explore the full range of supported tenancy approaches, see the vCluster tenancy models guide:
https://www.vcluster.com/guides/tenancy-models-with-vcluster
By decoupling the experience teams have from the infrastructure that supports it, this progression prevents disruptive platform transitions as Kubernetes adoption matures. It avoids the inefficiency of cluster proliferation, the limitations of namespace-only isolation, and the operational chaos that often comes from stitching together ad-hoc solutions over time.
Instead, it provides a clean path from early adoption to an enterprise-grade Kubernetes platform.
At this point in the discussion, a natural question arises:
If cluster sprawl and multi-team scaling are the problem, what about platforms like Rancher, Spectro Cloud, or Rafay?
These tools are widely adopted in enterprise environments for good reason. They provide strong capabilities for managing Kubernetes at scale, including:
For organizations already operating many clusters, cluster management platforms can dramatically improve operational consistency. However, there is an important distinction to make.
Cluster management platforms assume that multiple clusters already exist. Their value lies in organizing and operating those clusters efficiently. They do not fundamentally change the isolation model that led to cluster multiplication in the first place.
In other words, they help manage cluster sprawl. They do not eliminate the architectural driver of cluster sprawl. This distinction becomes critical as Kubernetes adoption expands across teams.
When isolation is tied directly to clusters, growth naturally increases cluster count. A fleet management layer can make that growth easier to operate, but it does not reduce the number of clusters required to provide isolation and autonomy.
Control plane isolation addresses a different layer of the problem.
Instead of improving the management of many clusters, it reduces the need to provision a separate cluster per team in the first place. By shifting the isolation boundary from the cluster to the control plane, infrastructure can remain consolidated even as tenancy increases.
These approaches are not mutually exclusive.
In fact, they can complement each other. A cluster management platform can manage the underlying EKS infrastructure clusters, while control plane isolation reduces the number of clusters required to serve many teams.
The result is an architecture that scales Kubernetes adoption while avoiding the operational multiplication that typically follows cluster-per-team growth.
If isolation is defined at the control-plane level rather than the cluster level, what does the platform actually look like? This is where the discussion becomes concrete.
A scalable Kubernetes platform on AWS must support growth without multiplying operational burden. In practice, that means separating two concerns that are often conflated early on:
When those two concerns are decoupled, the architecture becomes both simpler and more durable.
At a high level, a scalable AWS-native platform model looks like this:

At the base is a shared EKS cluster (or a small number of shared EKS clusters), which acts as the infrastructure substrate. This is where worker nodes live, where autoscaling occurs, and where platform-level integrations are installed.
EKS remains the “real” cluster — the stable operational unit owned by the platform team.
To drive adoption efficiently, a shared node pool is used for non-production workloads such as dev, test, preview environments, and CI. This enables high consolidation and cost efficiency while still providing teams with independent Kubernetes environments.
This model is particularly effective because it reduces the idle capacity problem that often makes early Kubernetes adoption expensive.
As Kubernetes adoption expands into production and regulated workloads, the platform can introduce private node pools for workloads that require stronger workload separation, predictable performance, or compliance boundaries.
The key benefit is that this does not require spinning up new EKS clusters.
Isolation increases through infrastructure allocation, not through platform redesign.
On top of this shared infrastructure layer, each team operates in its own isolated Kubernetes control plane. This gives teams administrative autonomy while preventing common multi-team problems such as CRD conflicts, upgrade coupling, or cluster-wide blast radius.
Most successful platform implementations standardize on GitOps workflows. In AWS environments, this often means a GitOps controller such as ArgoCD deployed per team environment or per tenancy boundary. This allows teams to manage their own application lifecycles while the platform team retains consistent operational patterns.
IAM integration is one of the most important requirements for AWS-based enterprises. The architecture should support clear identity boundaries between teams, ideally using AWS-native identity mechanisms such as Pod Identity. This ensures that teams can deploy workloads that access AWS services while maintaining least-privilege access and auditable policies.
At scale, Kubernetes platforms must assume dynamic workload demand. Autoscaling is not an optimization — it is foundational. A reference architecture should include cluster autoscaling and node provisioning automation (such as Karpenter) so infrastructure scales with demand without manual intervention.
A platform that supports dozens of teams must include centralized logging, monitoring, and cost governance. Teams need visibility into their environments, while platform owners need organizational visibility across tenants.
This often includes:
The goal is not just technical observability, but organizational accountability.
A typical scalable AWS Kubernetes platform includes:
The architecture is designed to scale Kubernetes adoption without forcing platform teams into managing an ever-growing fleet of clusters.
The biggest mistake organizations make when scaling Kubernetes adoption is treating the platform rollout as a single migration event. In practice, successful adoption happens in stages, with increasing levels of standardization and isolation over time.
A rollout strategy should optimize for two outcomes simultaneously:
A practical rollout approach looks like this.

Begin with two or three teams that are motivated and representative. The goal is to validate the platform model with real workloads, not to create a “perfect” reference implementation in isolation.
This stage is most effective when focused on dev and test workloads, where iteration is fast and risk is low.
Guardrails are what prevent platform success from becoming platform chaos.
As adoption begins, introduce:
This prevents the platform team from becoming reactive later.
Ingress and TLS management are common sources of fragmentation. Without a standard approach, every team invents its own routing, certificate strategy, and traffic management model.
Standardizing this early prevents long-term platform divergence and improves reliability.
Once the foundation is proven, expand the platform offering. At this stage, the objective is not to onboard every workload immediately, but to create a repeatable internal experience that teams trust.
This is where self-service becomes critical. The platform must be easy enough to use that adoption becomes natural rather than forced.
As production workloads move onto Kubernetes, some teams will require stronger separation, predictable performance, or compliance-driven workload isolation.
Instead of provisioning a new EKS cluster per team, introduce private node pools for those workloads. This allows isolation requirements to increase without changing the platform model.
Once adoption expands, cost becomes one of the most visible concerns. Kubernetes environments that run continuously, especially in dev/test, often waste significant capacity.
At this stage, introduce lifecycle automation such as:
This is where organizations can meaningfully reduce the operational and financial friction of Kubernetes adoption.
At scale, Kubernetes must be treated like a product, not a cluster.
This is the point where many organizations formalize an internal platform offering with:
The result is a repeatable, scalable experience that increases adoption without overwhelming the platform team.
The strongest platform architectures are not defined by abstractions alone. They are validated by practical use cases that appear repeatedly across organizations.
The following use cases commonly emerge as Kubernetes adoption expands.
As more teams move onto Kubernetes, developers want environments they can provision without waiting on platform tickets. The platform must support rapid creation of isolated Kubernetes environments while keeping infrastructure consolidated.
This is often the first stage of broad adoption because the business risk is low and the velocity gain is immediate.
Preview environments allow teams to deploy ephemeral instances of an application for manual review, stakeholder validation, or integration testing. These environments need to be easy to provision and easy to tear down.
At scale, preview environments are one of the biggest drivers of cluster sprawl unless the platform includes lifecycle automation.
CI pipelines often require isolated Kubernetes environments to run integration tests, validate Helm charts, or test controllers and CRDs. These environments must be reproducible, disposable, and cost efficient.
Without a scalable tenancy model, CI environments often lead to excessive cluster creation and wasted compute.
Many organizations aim to provide Kubernetes as an internal service, where teams can consume Kubernetes environments as needed while the platform team retains governance and operational control.
This use case requires a platform model that supports:
It is difficult to achieve using cluster-per-team models without driving cost and operational complexity.
As adoption matures, production workloads introduce stricter requirements around performance, compliance, and workload isolation.
A scalable architecture must support stronger separation without requiring a separate EKS cluster for every production team. This is where private node pools and progressive tenancy strategies become essential.
Many enterprises deploy third-party vendor platforms or shared internal services on Kubernetes. These workloads often require strict boundaries, predictable upgrades, and clear ownership.
A scalable platform model allows these services to run on shared infrastructure while maintaining separation between workloads and teams.
The most important lesson of enterprise Kubernetes adoption is that Kubernetes does not become difficult because it stops working. It becomes difficult when the organizational model cannot scale with adoption.
When isolation is tied to clusters, growth multiplies clusters. When isolation is limited to namespaces, autonomy becomes constrained.
When isolation is defined at the control-plane level, infrastructure and governance can evolve independently.
This separation is what allows Kubernetes adoption to expand from a small footprint to a majority of the estate without forcing repeated platform redesign.
Kubernetes adoption is not a single migration. It is an organizational evolution.
The platforms that succeed are the ones that plan for that evolution early.
If you are scaling Kubernetes adoption on AWS and want to avoid cluster sprawl, platform bottlenecks, and repeated re-architecture, control plane isolation provides a scalable foundation for delivering Kubernetes as a service across teams.
To learn more about virtual clusters and how vCluster enables multi-team Kubernetes adoption on EKS, explore the vCluster documentation or try vCluster in your environment.
Deploy your first virtual cluster today.
